谷歌真·AI配音神器来了!自动看懂画面、对齐音频,能为任何视频生成无数音频
发布日期:2024-06-24 16:36 点击次数:111

编译 | 陈骏达
编辑 | 程茜
智东西6月18日消息,今日凌晨,谷歌DeepMind发布了一个名为V2A(Video-to-Audio)的系统,能根据画面内容或者手动输入的提示词直接为视频配音。它还可以为任何视频输入生成无限数量的音轨。
谷歌DeepMindV2A系统最大的特点就是无需人工输入提示词也可以为视频配音。DeepMind在博客中称V2A能依靠自己的视觉能力理解视频中的像素。也就是说,V2A能看懂画面,知道画面里正在发生什么,应该出现什么声音。
打开新闻客户端 提升3倍流畅度▲谷歌DeepMind发布的V2A Demo视频
当然,V2A也能够根据提示词生成所需的音频。使用者可以通过输入“正面提示词”来引导模型输出所需的声音,或输入“负面提示词”来引导其避免出现不需要的声音,这给了使用者更大的控制权。
与其它AI音频生成工具不同,V2A在生成音频后无需人工对齐音频视频,而是可以直接自动将音频与画面对齐。
但谷歌DeepMind也承认,这一系统目前仍然存在很大的局限性。如果输入的视频质量不高,那么输出的音频质量也会出现明显的下降。他们认为需要进一步提升系统安全性并补齐当前V2A在口型同步等方面的短板,才能正式向公众发布这一系统。
谷歌发布V2A没过几小时,语音克隆创企ElevenLabs就发布了文字到音频模型的API,并基于这一API做了一个Demo应用让公众免费使用。
打开新闻客户端 提升3倍流畅度▲ElevenLabs最新应用给Luma生成的视频配音
与V2A不同的是,该应用并不能直接实现画面到音频的转换,而是利用了GPT-4o将视频截图转换为文字提示词,之后再输入文字转在几秒内生成多条与画面内容匹配的音频。这是基于该公司5月底发布的文字到音频模型打造的。
一、与自家Veo模型配合生成有声视频,但对复杂画面理解存在缺陷
虽然目前Sora、Pika、可灵以及近期的Dream Machine和Runway Gen-3 Alpha等一系列视频生成模型已经能输出逼真的视频画面,但它们生成的视频都是没有声音的。
AI工具也可以直接生成质量尚可的音频。AI创企Stability AI发布的Stable Audio Open模型可以输出长达47秒的乐器演奏片段,语音克隆初创公司ElevenLabs发布的音频生成工具可以根据用户输入的提示词生成音频。然而,目前没有工具可以全自动将视频与音频相结合,为AI生成的视频配音将是让AI视频变得更为真实的重要一步。
谷歌DeepMind推出V2A系统就是为了解决这一问题。谷歌DeepMind的博客中写道,V2A可与谷歌自家的Veo等视频生成模型配合使用,直接生成有声音的AI视频,V2A也可用于历史档案画面配音、无声影片配音等领域。
在下方的视频中,V2A展现出了对画面和提示词的超强理解能力。配乐营造出了提示词中紧张的恐怖片般的氛围,且音频与视频几乎完全同步。脚步声基本符合人物走动的节奏,随着画面的切换,脚步声也瞬间消失了。
打开新闻客户端 提升3倍流畅度▲音频提示词:电影风、惊悚片、恐怖片、音乐、紧张、氛围、混凝土上的脚步声
在下方的这则视频中,V2A生成的音乐婉转悠扬,配乐后的视频颇有西部大片般的感觉。
打开新闻客户端 提升3倍流畅度▲音频提示词:草原上夕阳西下时,悠扬柔和的口琴声响起
谷歌DeepMind发布的Demo视频中也出现了不少破绽。下方的视频是一位鼓手在演奏架子鼓。而V2A生成的第一秒音频还相对符合画面中的演奏节奏和所击打的鼓,然而后面的音频却出现了不属于这一画面的声音。画面中鼓手一直演奏的是架子鼓中的军鼓,然而音频中却出现了击打架子鼓其它部分(嗵鼓)的声音。这显示出V2A对复杂画面的理解尚存在缺陷。
打开新闻客户端 提升3倍流畅度▲音频提示词:音乐会舞台上的鼓手,周围环绕着闪烁的灯光和欢呼的人群
V2A还有一个特点就是给了创作者很大的自由。它可以为任何视频输入生成无限数量的音轨,还可以给模型定义“正面提示”以引导模型输出所需的声音,或定义“负面提示”以引导其避免出现不需要的声音。
这种灵活性使用户可以更好地控制V2A的音频输出,让用户可以可以快速尝试不同的音频输出并选择最佳匹配。
打开新闻客户端 提升3倍流畅度▲视频1(音频提示词:空灵的大提琴氛围)
打开新闻客户端 提升3倍流畅度▲视频2(音频提示词:宇宙飞船在浩瀚的太空中疾驰,星星划过,高速,科幻)
上方2个视频是V2A根据同一段视频生成的不同音频效果。只需简单调整提示词,V2A就能迅速给创作者提供风格迥异的音频。
二、采用基于扩散的高质量音频输出,AI给视频加注释辅助训练
谷歌DeepMind的研究人员称,他们一开始尝试了自回归和扩散这两种技术路径,发现基于扩散的音频生成方法为同步视频和音频信息提供了最真实的输出结果。
V2A系统首先会将视频输入编码为压缩表征,然后扩散模型迭代地从随机噪声中提炼音频。该过程由视觉输入和自然语言提示引导,以生成高度符合提示词的音频。最后,音频输出被解码,转换为音频波形并与视频数据组合。
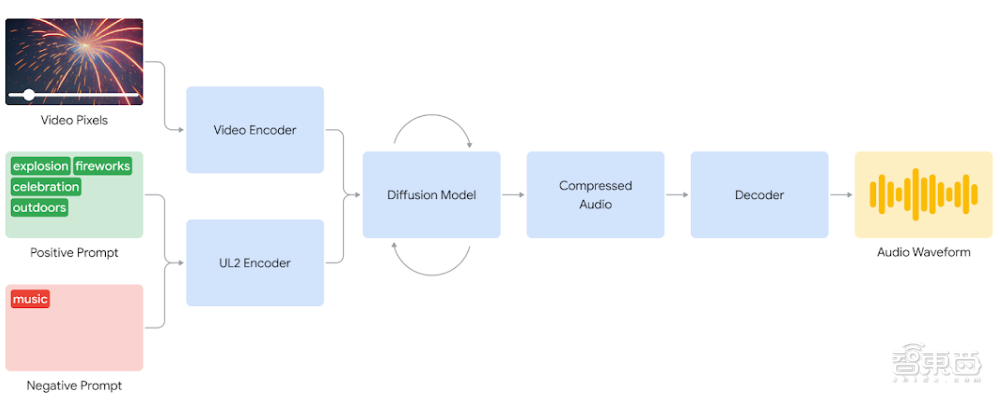
为了生成更高质量的音频并增加引导模型生成特定声音的能力,谷歌DeepMind的研究人员在训练过程中添加了更多信息。这些信息是AI根据视频生成的注释,包括对画面内声音的详细描述和画面中的口语对话的记录。
通过使用视频、音频和附加注释进行训练,V2A系统学会了将特定的音频事件与各种视觉场景相关联,同时还能理解提示词中提供的信息。
博客中写道,V2A系统可以理解原始像素,将文本提示变为可选项。这意味着V2A可以直接看懂视频画面并据此生成音频。这一系统也不需要人工将生成的声音与视频对齐,创作者不需要经历繁琐的调整过程。
尽管目前这一系统已经初具成效,但DeepMind的研究人员认为目前这一系统仍然存在缺陷。它的音频输出质量严重依赖于视频输入的质量,视频中的伪影或失真会导致音频质量的严重下滑。
此外,研究人员还在不断改进系统的口型同步能力,目前V2A在这方面表现不佳。在下方的视频中,虽然V2A只生成了一位小女孩的说话声,但是画面中所有人物的口型都在变化,并且与说话内容并不一致。
打开新闻客户端 提升3倍流畅度▲音频提示词:音乐、对话内容:“这只火鸡看起来棒极了,我太饿了。”(Music, Transcript: “This turkey looks amazing, I’m so hungry.”)
虽然V2A可以按照输入文本生成人物对话的音频,并基本与画面中角色的口型同步。但口型同步的效果与视频生成模型相关,如果视频生成模型没有对口型的能力,口型同步的效果便会大打折扣。
三、ElevenLabs开源视频配音应用,部分效果不如V2A
5月31日,同样在AI声音生成赛道上的ElevenLabs发布了他们最新的AI音频模型,可以通过文本提示生成音效、乐器演奏片段和各种角色声音。
在ElevenLabs发布的宣传片中,他们的AI音频模型展现出了不俗的能力。它能一次生成多段音效供创作人员选择,在口型同步上表现也不错。ElevenLabs认为这一模型在游戏行业和影视行业中有较大的应用前景。
打开新闻客户端 提升3倍流畅度就在谷歌DeepMind发布V2A系统后不久,ElevenLabs就上线了他们的文本到声音效果API,并基于API做了一个开源的视频到声音效果的应用。智东西第一时间测试了这一应用的生成效果,我们将谷歌Demo中的视频消音后输入了ElevenLabs的开源应用,让其生成音频。
打开新闻客户端 提升3倍流畅度▲ElevenLabs产品给谷歌Veo生成的视频配音
就这一视频而言,ElevenLabs的应用要逊色于谷歌V2A系统。视频前半部分的脚步声频率基本与画面相符,但在切换镜头后音频就与画面不匹配了。此外,由于不支持人工提示词输入,视频没有配上适合的背景音乐。
ElevenLabs的研究人员称,他们的视频到声音应用在不到一天的时间内开发出来了。该应用自动将视频按照每秒截取四帧的频率截图,并发送给GPT-4o模型,将画面内容转为文字提示词。提示词将输入到他们的文字到音频模型中,模型会生成符合画面内容的音频。
结语:V2A系统尚不对外开放,开发者需要对模型潜在风险负责
谷歌DeepMind目前并不打算向公众开放V2A系统。他们目前在与创作者进行沟通,收集创作者的看法与建议然后进一步优化V2A系统。
谷歌DeepMind强调,他们特别将SynthID工具包(谷歌标记AIGC的特殊水印)纳入到V2A研究中,为所有AI生成内容添加水印,防止滥用该技术的可能性。
ElevenLabs的音频模型和谷歌DeepMind的V2A系统的相继发布,或将给内容创作的生态带来巨大的改变。而正如之前所有AI模型那样,音频生成模型也面临着滥用的风险。这将是摆在开发者面前的重要挑战。